Understanding Image Generation with Diffusion
Explore the working of models like Stable Diffusion, Midjourney and DALL-E

Introduction
The ability to generate images from simple text prompts and minimal configuration is a recent development and has tremendous applications, from art and entertainment to medical research. While there have been many attempts in the past to crack image generation, a new technique called diffusion has gained massive popularity in a very short amount of time.
In this blog post, we will explore what diffusion is and how it can be used to generate high-quality images. We also explore how to use base and customised Stable Diffusion models locally.
History of image generation
While there were a few attempts to generate images using algorithms in the early days of computing, these usually included simple rule-based methods and procedural generation techniques. However, these methods were limited in their ability to produce high-quality images with rich details and textures. The main focus in the initial days of computing was more to identify text than creating it — since this was significantly more valuable to the community at large.
As an example, one of the first machine learning applications to be used on a large scale was in the US post office for reading zip codes on envelopes.

By Cmglee — Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=104937230
This technology was based on a neural network architecture called LeNet-5. While LeNet-5 was a significant milestone in machine learning, it was limited in its ability to handle more complex tasks.
The computational power and theoretical understanding required to tackle image generation developed much later.
Generative Adversarial Networks (GANs)
Generative adversarial networks (GANs) are a type of machine learning model that can be used to generate new data. GANs were first introduced in a 2014 paper by Ian Goodfellow and have since become one of the most popular techniques for image generation. GANs consist of two neural networks: a generator and a discriminator.

They consist of two parts:
the generator network, which generates images from random noise
the discriminator network, which tries to distinguish between real and generated images.
The generator and discriminator are trained together in a process called adversarial training. In adversarial training, the generator tries to create data that is so realistic that the discriminator cannot distinguish it from real data. The discriminator, on the other hand, tries to become better at distinguishing between real data and data generated by the generator.
As the generator and discriminator are trained, they become increasingly better at their respective tasks. Eventually, the generator becomes so good at creating realistic data that the discriminator cannot distinguish it from real data.
While GANs have been successful in generating high-quality images, they can be difficult to train and suffer from issues such as mode collapse.
Diffusion models
A diffusion model is a type of generative model that can be used to generate images. Diffusion models work by starting with a noise image and then gradually adding detail to the image until it becomes a realistic image.
There were several papers that established the ideas that Diffusion models are based on but the key paper was Denoising Diffusion Probabilistic Models published in 2020.
The name “diffusion” comes from the fact that the model starts with a high-entropy image (i.e., a random image with no structure) and then gradually diffuses the entropy away, making the image more structured and realistic.
Diffusion models are a relatively new type of generative model, but they have been shown to be able to generate realistic images. They are also often faster to train than other types of generative models, such as GANs.
Basics of Diffusion
Training a Diffusion model usually starts with taking an existing image and add Gaussian noise to the image in multiple iterations. The model learns by trying to recreate the original image from the Gaussian noise. Loss is calculated from how different the final image is from the original image.

Source: https://developer.nvidia.com/blog/improving-diffusion-models-as-an-alternative-to-gans-part-1/
When creating an image from a prompt, the first step is to create a noise image. This is typically done by generating a random image with a high level of entropy. The entropy of an image is a measure of how random the image is. A high-entropy image is a random image with no structure, while a low-entropy image is a structured image with a lot of detail.

Image source: Ho et al. 2020
The second step is to gradually add detail to the noise image. This is done by using a diffusion process. A diffusion process is a mathematical model that describes how the entropy of an image changes over time. The diffusion process is used to gradually add detail to the noise image while keeping the overall structure of the image intact.
The diffusion process is typically implemented as a neural network. The neural network is trained on a dataset of real images. The training process teaches the neural network how to add detail to noise images in a way that is consistent with the training data. Once the neural network is trained, it can be used to generate realistic images.
Summing up:
Generate a noise image with a high level of entropy.
Use a diffusion process to gradually add detail to the noise image.
Use a neural network to control the diffusion process.
Generate a realistic image by running the diffusion process until the desired level of detail is reached.
The noising and denoising process used in a diffusion model is a powerful technique for generating realistic images. The process is relatively simple to implement, and it can be used to generate images from a variety of different domains.
Why is Diffusion better than GANs?
In terms of why diffusion is quicker than GANs, one reason is that diffusion models do not require the two-step process of training separate generator and discriminator networks. Instead, diffusion models are trained end-to-end using a single loss function.
One of the main advantages of diffusion models is that they are easier to train. GANs can be difficult to train, and they often require a lot of hyperparameter tuning. Diffusion models, on the other hand, are relatively easy to train, and they can often achieve good results with a relatively small amount of data.
Another advantage of diffusion models is that they are more stable. GANs can be unstable, and they can sometimes generate images that are not realistic or that are not consistent with the training data. Diffusion models, on the other hand, are more stable, and they are less likely to generate images that are not realistic.
Finally, diffusion models are more versatile than GANs. Diffusion models can be used to generate images from a variety of different domains, including natural images, medical images, and artistic images. GANs, on the other hand, are typically used to generate natural images.
Concepts related to Diffusion
Checkpoints
A checkpoint is a file that contains the state of a Stable Diffusion model at a particular point in its training. This includes the weights of the model, as well as any other training data that was used to train the model.
Checkpoints are used to save the progress of training a Stable Diffusion model so that the training can be resumed from a previous point if it is interrupted or fails. Checkpoints are also used to save the best model that has been trained so far, which can be used to generate images or to continue training the model from that point.
The checkpoint file for a Stable Diffusion model is typically a large file, as it contains the weights of the model, which can be several gigabytes in size. Checkpoint files are typically saved in a format that can be easily loaded by the Stable Diffusion library. Most websites offer checkpoints in a .ckpt or a .safetensors format.
Hypernetworks
A hypernetwork is a small neural network that is attached to a Stable Diffusion model to modify its style. It is trained on a dataset of images that have the desired style and then used to generate images with that same style.
The hypernetwork is inserted into the most critical part of the Stable Diffusion model, the cross-attention module of the noise predictor UNet. This module is responsible for determining how the noise is used to generate the image, and the hypernetwork can be used to change the way that the noise is used to create a different style.
Training a hypernetwork is relatively fast and requires limited resources, as the hypernetwork is much smaller than the Stable Diffusion model itself. This makes it a very convenient way to fine-tune a Stable Diffusion model to a specific style.
LoRA
LoRA stands for Low-Rank Adaptation. It is a training technique for fine-tuning Stable Diffusion models. LoRA models are small Stable Diffusion models that apply tiny changes to standard checkpoint models. They are usually 10 to 100 times smaller than checkpoint models.
The use of LoRA models has several benefits. First, LoRA models are much smaller than checkpoint models, which makes them easier to store and transfer. Second, LoRA models can be trained quickly, which makes them a good option for fine-tuning models on a variety of concepts. Third, LoRA models can be used to improve the quality of images generated by Stable Diffusion models.
Textual Inversion
Textual inversion is a technique for teaching a stable diffusion model to understand new concepts from a small number of example images. The technique works by first training a text encoder to map text prompts to a latent space. The latent space is then used to condition the stable diffusion model, which helps the model understand the prompt and new concepts from just a few example images.
Once the text encoder is trained, it can be used to teach the stable diffusion model to understand new concepts. To do this, a small number of example images are selected that represent the new concepts. The text prompts for these images are then used to generate latent spaces. These latent spaces are then used to condition the stable diffusion model, which helps the model learn to generate images that match the new concepts.
Textual inversion files are the smallest files to fine-tune the results of the Diffusion model — usually on the order of Kilobytes.
Variational AutoEncoder (VAE)
A variational autoencoder (VAE) is a type of generative model that can be used to generate images, text, and other data. The VAE consists of two parts: an encoder and a decoder. The encoder takes input data and compresses it into a latent representation. The decoder then takes the latent representation and reconstructs the input data.
In the context of stable diffusion, the VAE can be used to improve the stability and robustness of the diffusion model. The VAE is used to compress the image into a latent space, which is a much smaller dimensional space than the original image. This makes it easier for the diffusion model to learn the latent space, and it also makes the diffusion model more robust to noise in the image.
Using Diffusion models locally
One of the best tools for using Diffusion models locally is Auto1111 (or AUTOMATIC1111). There is also a widely used fork of Auto1111 often called VladDiffusion which you can find here.
AUTOMATIC1111 is a free and open-source web user interface for the Stable Diffusion model, a generative adversarial network (GAN) that can be used to create realistic images from text prompts.
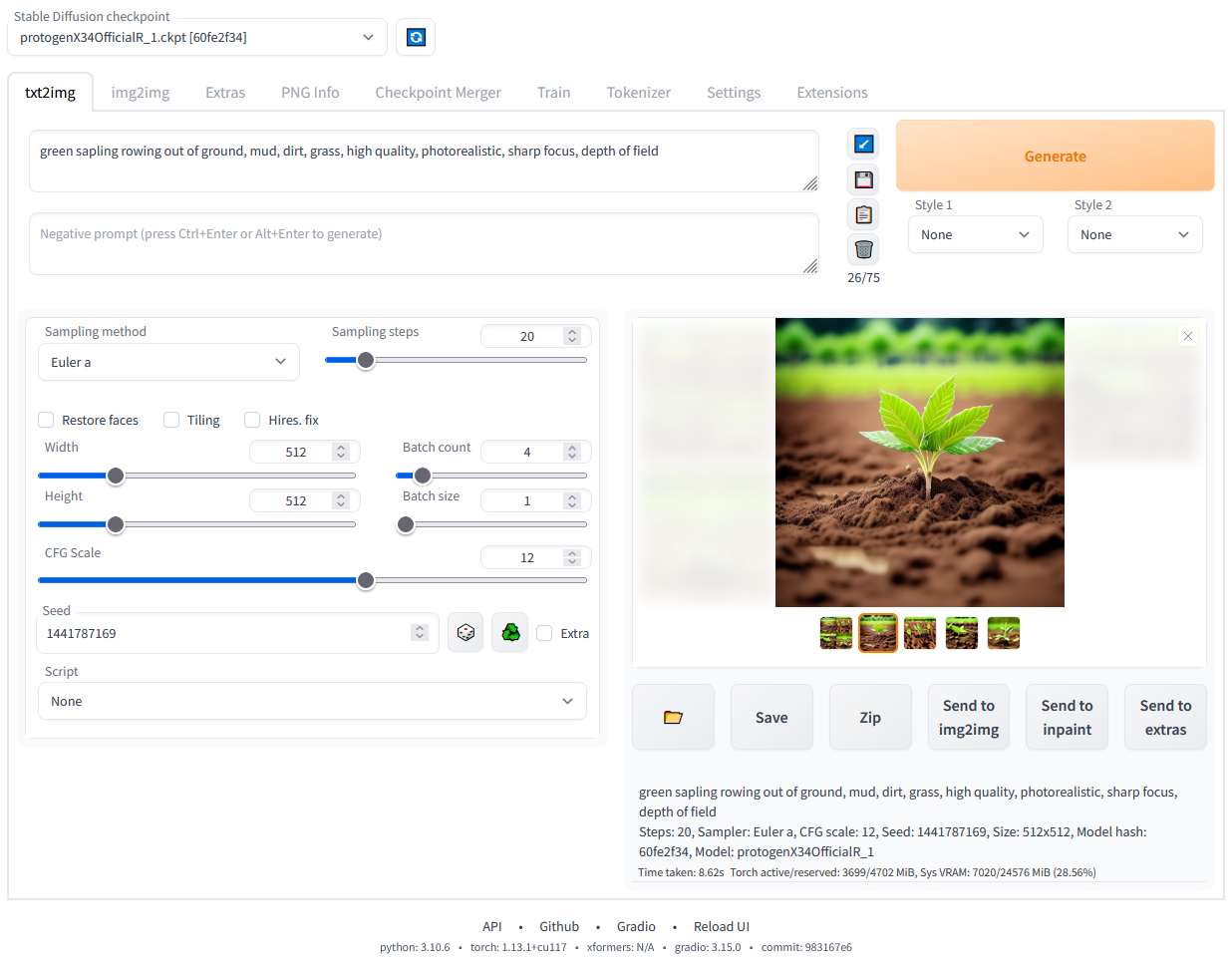
You can select the model you intend to use through the dropdown at the top of the interface. Download the models you require and place them in the ‘models’ folder to use them.
The ‘txt2img’ tab deals with generating images through text prompts. You can also use additional extensions such as ControlNet through this tab. The ‘img2img’ tab deals with transforming images — such as through inpainting, outpainting, and more. There are also additional options to train your own models and download extensions to make the UI even more functional. There are several extensions like Dreambooth which allow you to train your own models, hypernetworks, and more. I will be publishing more articles regarding training and using custom models, LoRAs, hyper networks, and textual inversion.
Popular Diffusion tools
Stable Diffusion
Stable Diffusion was created by researchers at Stability AI, a start-up company based in London and Los Altos, California. The model was developed by Patrick Esser of Runway and Robin Rombach of CompVis, who were among the researchers who had earlier invented the latent diffusion model architecture used by Stable Diffusion.
DALL-E
DALL-E is a generative model developed by OpenAI that can be used to generate images from text descriptions. DALL-E was first announced in January 2021, and it quickly became one of the most popular generative models in the world. It has been used to generate a wide variety of images, including realistic images of animals, objects, and people, as well as more creative images such as paintings and sculptures.
Midjourney
Midjourney is a generative AI program and service created and hosted by San Francisco-based independent research lab Midjourney, Inc. Midjourney generates images from natural language descriptions, called “prompts”, similar to OpenAI’s DALL-E and VQGAN+CLIP. Midjourney was founded in 2021 by David Holz, previously co-founder of Leap Motion. The Midjourney image generation platform first entered open beta on July 12, 2022.
Midjourney is exclusively available through Discord — probably the most unorthodox approach of all the models listed.
Open-source models
You can also find more custom open-source models at various sites such as HuggingFace.

